在Raspberry pi 3b上配置Pytorch运行环境
安装Pytorch和Torchvision
Pytorch和torchvision目前不支持Raspberry Pi的架构(armv7l和arch64),所以一般会用这种方法创建一个虚拟环境,然后从这些库中生成.whl文件。
我是懒狗,所以我用https://github.com/marcusvlc/pytorch-on-rpi给的现成轮子,因此下面多数内容只是翻译了一下里面的文档
第一步当然是git clone https://github.com/marcusvlc/pytorch-on-rpi.git
然后...
# 安装 Pytorch
sudo python -m pip install torch-1.4.0a0+7f73f1d-cp37-cp37m-linux_armv7l.whl
# 安装 Torchvision
sudo python -m pip install torchvision-0.5.0a0+85b8fbf-cp37-cp37m-linux_armv7l.whl
执行 import torch , 会发生错误:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.6/site-packages/torch/__init__.py", line 45, in <module>
from torch._C import *
ModuleNotFoundError: No module named 'torch._C'需要找到你的Python安装路径,如果你没有用虚拟环境的话一般是 /usr/local/lib/python3.7/dist-packages/torch
在文件夹内应该有如下两个文件:
_C啥啥啥啥啥啥.so
_dl啥啥啥啥啥啥.so需要把这两个文件后面的啥啥啥都删了,只剩下
_C.so
_dl.so现在应该就好了

GPT-2需要的包
安装Rust编译器 curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
随后重启终端
安装interact.py所需包 pip install tqdm numpy dataset scikit_learn train
对这个tokenizers要三四个小时,卡住了哪怕CPU和IO一个都没在动也要等...
最后要安装tensorboard,在装之前先改个源
为什么不一开始就改呢?因为tranformers里有一个包,国内的镜像源都没有,用到默认的pythonhosted.org总是会自动断开
vim /etc/pip.conf
[global]
index-url= https://mirrors.aliyun.com/pypi/simple/
extra-index-url= https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=
mirrors.aliyun.com
files.pythonhosted.org
pypi.org
pypi.tuna.tsinghua.edu.cn在/etc/dphys-swapfile改了SWAP分区大小
...
CONF_SWAPSIZE=2000
....使用/etc/init.d/dphys-swapfile restart重启服务
当然是pip install tensorboard,同样需要卡好久好久
在安装 transformers==2.1.1 之前,他的依赖sentencepiece目前还不支持Raspberry Pi,但是可以安装更新的 transformers,至少在这里可以运作:
pip install transformers==4.0.0
因为不需要sentencepiece,所以他能安装成功
运行interact.py,会发现报错No module named 'transformers.modeling_gpt2' GPT2LMHeadModel
那去找文件复制进去就好了,一共需要这样两个文件,configuration_gpt2.py以及modeling_gpt2.py,放入/usr/local/lib/python3.7/dist-packages/transformers,
安装 libatlas,apt-get install libatlas-base-dev为预防可能的libf77blas.so.3: cannot open shared file: no such file or directory错误
最后一步了,运行本体,会出现错误:
File "/usr/local/lib/python3.7/dist-packages/transformers/modeling_gpt2.py", line 552, in forward
use_cache = use_cache if use_cache is not None else self.config.use_cache
AttributeError: 'GPT2Config' object has no attribute 'use_cache'他说552行有问题,那就把552行删掉,随后运行python interact.py,完成

不要想办法装2.1.1的transformers, sentencepiece的每一条关于
pkg-config的issues一条条看过来都不行
NoneBot2 + go-cqhttp
先安装NoneBot2: pip install nonebot2
然后下载坠新的go-cqhttp
初始什么的,照着文档抄呗,然后看完它
看完它之后,你的目录应该是这样的:
Go-cqhttp
├── Nonebot2
│ ├── awesome_bot
│ │ └── plugins
│ │ └── foo
│ │ └── __init__.py
│ ├── bot.py
│ ├── docker-compose.yml
│ ├── Dockerfile
│ ├── README.md
├── codec
│ └── ...
├── config.hjson
├── data
│ └── ....
├── device.json
├── go-cqhttp
└── requirements.txt
随便是新建还是改名,在plugins/下把gpt-2_chitchat下生成需要的文件放到一个文件夹,再将dialogue_model/以及vocabulary/放到Nonebot2/目录下,结果应该是这样子的
Go-cqhttp
├── Nonebot2
│ ├── qqbot
│ │ └── plugins
│ │ ├── chitchat-plugin
│ │ │ ├── dataset.py
│ │ │ ├── generate_dialogue_subset.py
│ │ │ ├── __init__.py
│ │ │ ├── interact.py
│ │ │ └── train.py
│ ├── bot.py
│ ├── dialogue_model
│ │ ├── config.json
│ │ └── pytorch_model.bin
│ ├── docker-compose.yml
│ ├── Dockerfile
│ ├── README.md
│ └── vocabulary
│ └── vocab_small.txt
├── codec
│ └── ...
├── config.hjson
├── data
│ └── ....
├── device.json
├── go-cqhttp
└── requirements.txt
.env.*文件中,把指令设为空
COMMAND_START=["/", ""]
在bot.py下的插件加载应是
nonebot.load_plugins("bot1/plugins/")
接下来就是跑了,你总要来个screen吧
apt-get install screen
然后开个叫做go-cqhttp的session,运行go-cqhttp
screen -S go-cqhttp
/home/Projects/QQbot/./go-cqhttp

运行完退出来Ctrl + a ,再按d
再开个用来跑Nonebot的session
screen -S nonebot
python bot1/bot.py
可以用了
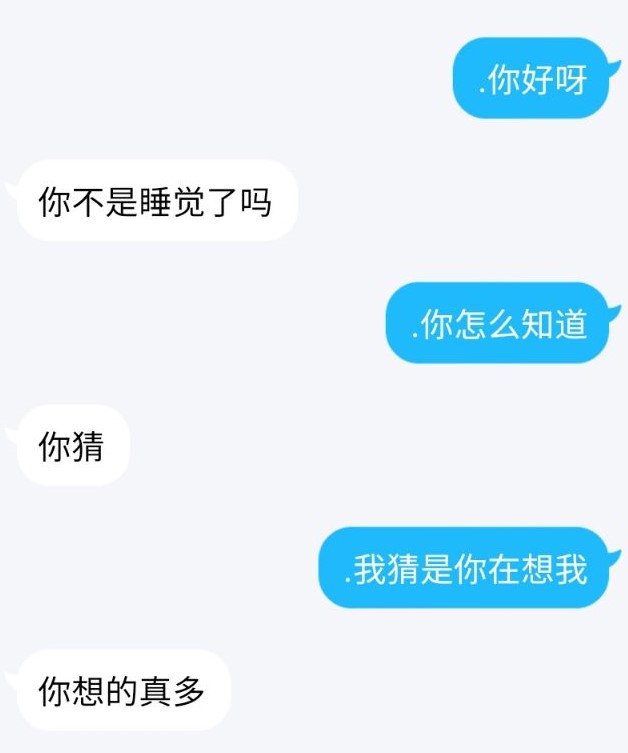
最后是几个又臭又长的文件:
# .../Go-cqhttp/Nonebot2/qqbot/plugins/chitchat-plugin/interact.py
import torch
import os
import json
import random
import numpy as np
import argparse
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
from tqdm import tqdm
from torch.nn import DataParallel
import logging
from transformers.modeling_gpt2 import GPT2Config, GPT2LMHeadModel
from transformers import BertTokenizer
from os.path import join, exists
from itertools import zip_longest, chain
from .dataset import MyDataset
from torch.utils.data import Dataset, DataLoader
from torch.nn import CrossEntropyLoss
from sklearn.model_selection import train_test_split
from .train import create_model
import torch.nn.functional as F
PAD = '[PAD]'
pad_id = 0
device = 'cpu'
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
tokenizer = BertTokenizer(vocab_file='vocabulary/vocab_small.txt')
model = GPT2LMHeadModel.from_pretrained('dialogue_model/')
model.to(device)
model.eval()
history = []
def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
assert logits.dim() == 1
top_k = min(top_k, logits.size(-1))
if top_k > 0:
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
logits[indices_to_remove] = filter_value
if top_p > 0.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
sorted_indices_to_remove = cumulative_probs > top_p
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[indices_to_remove] = filter_value
return logits
def mainchat(input_content):
text = input_content
history.append(tokenizer.encode(text))
input_ids = [tokenizer.cls_token_id]
for history_id, history_utr in enumerate(history[-5:]):
input_ids.extend(history_utr)
input_ids.append(tokenizer.sep_token_id)
curr_input_tensor = torch.tensor(input_ids).long().to(device)
generated = []
for _ in range(25):
outputs = model(input_ids=curr_input_tensor)
next_token_logits = outputs[0][-1, :]
for id in set(generated):
next_token_logits[id]
next_token_logits = next_token_logits
next_token_logits[tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf')
filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=8, top_p=0)
next_token = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1)
if next_token == tokenizer.sep_token_id:
break
generated.append(next_token.item())
curr_input_tensor = torch.cat((curr_input_tensor, next_token), dim=0)
history.append(generated)
text = tokenizer.convert_ids_to_tokens(generated)
res = "".join(text)
print(res)
return res
if __name__ == '__main__':
while 1:
mainchat(input('对话:'))还有一个是照抄官方例子的
# .../Go-cqhttp/Nonebot2/qqbot/plugins/chitchat-plugin/__init__.py
from nonebot import on_command
from nonebot.rule import to_me
from nonebot.adapters.cqhttp import Bot, Event
from .interact import mainchat
chitchat = on_command(".", rule=to_me(), priority=4) # 回复所有就把点去掉
@chitchat.handle()
async def handle_first_receive(bot: Bot, event: Event, state: dict):
args = str(event.message).strip()
if args:
state["chat_content"] = args
@chitchat.got("chat_content")
async def handle_city(bot: Bot, event: Event, state: dict):
chat_content = state["chat_content"]
reply_context = await get_reply(chat_content)
await chitchat.finish(reply_context)
async def get_reply(chat_content: str):
res = mainchat(chat_content)
return res